



2024년에는 어떤 일이 있었지? 워드클라우드로 돌아보는 2024 사회 이슈!
워드클라우드로 돌아보는 2024 사회 이슈!

한국PR협회가 2024년을 마무리하며 ‘올해의 소통 키워드 TOP 10’을 발표했어요. 이 키워드만 봐도 2024년에 어떤 일이 있었는지 한눈에 살펴볼 수 있는데요.
키워드를 중심으로 트렌드를 분석하는 콘텐츠를 만들 수 있다면, 데이터 활용 직무에 한 걸음 다가갈 수 있지 않을까요?
그래서 오늘은 키워드를 활용해 워드클라우드 만드는 방법을 소개해드리려고 해요!
워드클라우드는 단어의 등장 빈도에 따라 크기를 조정해, 자주 등장하는 단어는 더 크게 덜 등장하는 단어는 더 작게 나타내는 데이터 시각화 스킬이에요.
여기서 잠깐, 인공지능(AI)이 1위를 차지했네요! 인공지능이 크게 발전하며 2024년에 많은 관심을 받았죠. 그래서 데선배들도 레터에 생성형 AI와 관련한 내용을 자세히 다루었답니다. 그래서 오늘은 인공지능을 제외하고 2024년에 일어난 사회적 이슈에 대해서 다루어보려고 해요. 인공지능에 대해 궁금한 데후배들은 ‘ 문과도 Chat GPT로 데이터 분석할 수 있나요?’ 회차를 한 번 읽어보세요!
문과도 Chat GPT로 데이터 분석할 수 있나요?’ 회차를 한 번 읽어보세요!‘데선배들’에서는 올해의 소통 키워드 2위인 ‘의료대란’을 활용해 워드클라우드를 만들어 봤어요.

‘정부’, ‘의대’, ‘응급실’, ‘전공의’, ‘집단행동’과 같은 키워드가 눈에 띄는데요!
해당 키워드를 연결하는 식으로 뉴스 콘텐츠를 해석하면, 의료대란 이슈를 한 층 더 깊이 이해할 수 있겠죠?
데이터 비전공자도 쉽게 따라할 수 있으니, 다 함께 도전해보면 좋을 것 같아요 :)
텍스트 데이터는 뉴스 빅데이터 분석 플랫폼 ‘빅카인즈(Bigkinds)’에서 내려받을 수 있고, 워드클라우드는 파이썬(Python) 환경에서 직접 만들어볼 수 있어요.
파이썬은 코드 프로그래밍 언어로, 파이썬 코드를 작성하고 실행할 수 있는 공간을 파이썬 환경이라고 해요.
이번엔 구글 코랩(Google Colab)을 기준으로 설명해드릴게요!
오늘의 로드맵
데이터셋 다운받기 워드클라우드 생성하기•
데이터 불러오기
•
키워드 컬럼 추출하기
•
불용어 제거하기
•
한글 폰트 설치하기
•
워드클라우드 생성하기
Mask 적용하기데이터셋 다운받기
뉴스분석 카테고리의 ‘뉴스검색·분석’ 클릭 뉴스 검색에 원하는 키워드를 입력
뉴스 검색에 원하는 키워드를 입력저희는 한국PR협회의 올해의 소통 키워드 2위 ‘의료대란’을 입력했어요.
 ‘기간’ 설정
‘기간’ 설정저희는 2024년 4분기 트렌드 파악을 위해, 기간은 ‘3개월’로 설정했어요.
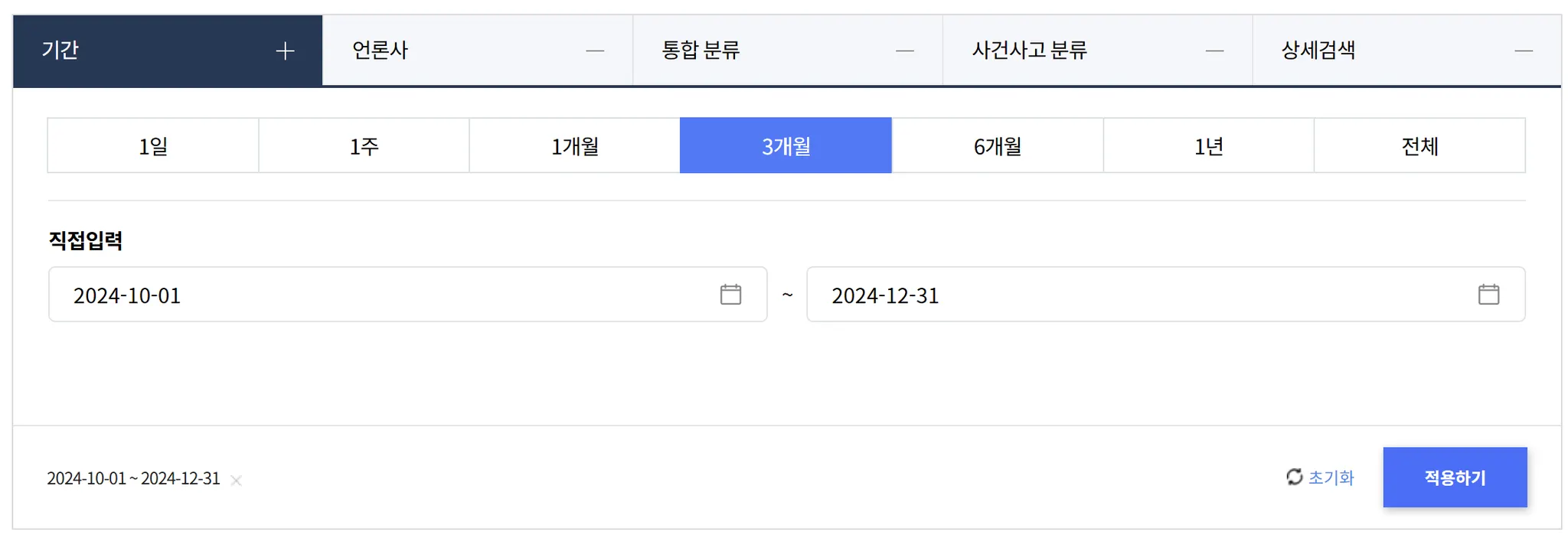
비회원은 3개월까지 기간 설정 가능하고 회원가입을 하면 1년까지 가능해요. 하지만 데이터를 다운받기 위해서는 반드시 로그인이 필요하답니다!
‘언론사’ 필터링국내 54개 언론사 중 원하는 매체의 기사만을 필터링할 수 있어요.
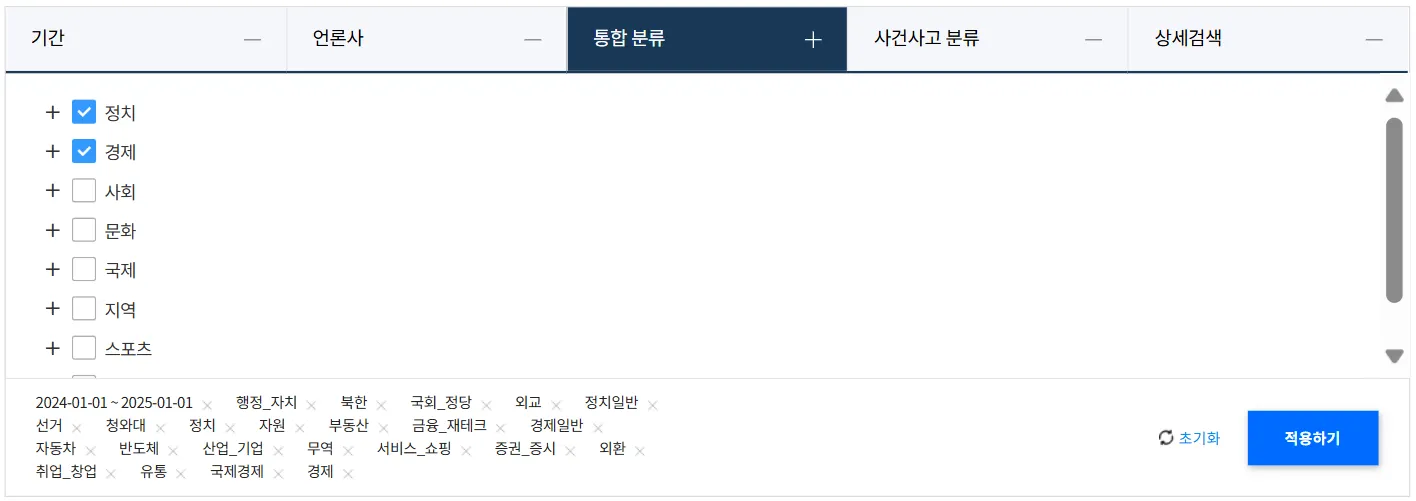
 ‘통합 분류’ 선택
‘통합 분류’ 선택원하는 분류를 필터링 해 기사를 볼 수 있어요. 꼭 필요한 기사만 필터링하기 위해 ‘정치’, ‘경제’ 분류만 체크했어요.
 검색 결과 확인
검색 결과 확인뉴스 검색 설정을 끝낸 후 ‘적용하기’를 클릭하면 검색 결과가 나와요.
 ‘데이터 다운로드’하기
‘데이터 다운로드’하기 ‘분석 결과 및 시각화’를 클릭 후, 오른쪽 하단 ‘엑셀 다운로드’를 클릭합니다. 일자, 언론사, 기고자, 제목, 키워드, 특성추출(가중치 상위 50개), 본문 등 분류된 데이터를 엑셀 파일로 다운받을 수 있어요.


워드클라우드 생성하기
•
데이터 불러오기
다운로드 받은 데이터는 csv 파일로 저장해서 구글 드라이브에 옮겨 주세요.
# 드라이브 마운트하기 (구글 드라이브와 구글 코랩을 연결하는 과정입니다)
from google.colab import drive
drive.mount('/content/drive')
Python
복사
# 엑셀 파일 불러오기
import pandas as pd
df = pd.read_csv("데이터셋 파일경로")
Python
복사
•
키워드 컬럼 추출하기
데이터셋 안의 키워드 컬럼을 추출해서 각각의 키워드를 리스트 형태로 저장할 거예요.
# '키워드' 컬럼만 추출 (NaN이 있을 경우 제거)
keywords = df['키워드'].dropna()
# 각 행마다 키워드를 구분자(예: 쉼표)로 나누어 tokens 리스트에 추가
tokens = []
for row in keywords:
# 쉼표(,)를 기준으로 split
split_words = row.split(',')
# 분리된 토큰들을 tokens 리스트에 확장
tokens.extend(split_words)
print(tokens[:50]) # 잘 들어갔는지 상위 50개 정도만 확인
Python
복사
•
불용어 제거하기
불용어란 분석에 큰 의미가 없는 단어들을 뜻합니다.
from collections import Counter
# 불용어 리스트 정의
stopwords = ['의료','의사','진료','교수','전공','병원','의료대란','의사들','대학','현장','상황','이날','보건']
# 불용어를 tokens에서 제거
filtered_tokens = [token for token in tokens if token not in stopwords]
# 불용어가 제거된 후의 키워드 카운트
filtered_nouns_counter = Counter(filtered_tokens)
Python
복사
이제부터 워드클라우드 생성에 filtered_nouns_counter를 사용할 것이니 주의해주세요!
•
한글 폰트 설치하기
워드클라우드를 정상적으로 출력하기 위해선 한글 폰트를 설치해야 해요. 파이썬의 워드클라우드 라이브러리는 한글을 인식하지 못하기 때문이죠.
# 1) 나눔 글꼴 설치
!apt-get update -qq
!apt-get install fonts-nanum -qq
# 2) 폰트 매니저에 폰트 등록
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
font_files = fm.findSystemFonts(fontpaths=['/usr/share/fonts/truetype/nanum'])
for font_file in font_files:
fm.fontManager.addfont(font_file)
# 3) wordcloud에 사용할 폰트 설정
plt.rc('font', family='NanumGothic') # or 'NanumBarunGothic'
Python
복사
•
워드클라우드 생성
# 라이브러리 임포트
from wordcloud import WordCloud, STOPWORDS
from collections import Counter
import matplotlib.pyplot as plt
# 워드클라우드 객체 생성
wc = WordCloud(
width=3000,
height=2000,
random_state=1,
background_color='white',
colormap='Set2',
collocations=False,
font_path='./font/NanumBarunGothic.ttf' # 폰트 경로 (본인 환경에 맞게 수정)
)
# filtered_nouns_counter의 단어-빈도 데이터를 활용하여 워드클라우드 생성
wc.generate_from_frequencies(filtered_nouns_counter)
# 워드클라우드 시각화
plt.figure(figsize=(12, 12))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
Python
복사
결과)

‘의료대란’ 키워드 관련 뉴스 데이터를 시각화한 워드클라우드입니다.
워드클라우드를 보다 창의적으로 표현할 수 있는 방법은 없을까요?
Mask 적용하기

청진기 아이콘을 이용해서 워드클라우드를 청진기 모양으로 만들어볼 거예요. 이처럼 원하는 이미지를 이용해 워드클라우드의 형태를 결정하는 과정을 ‘마스크 적용’이라고 부른답니다.
마스크를 적용하기 위해서는 이미지에 '순백색'(white)에 대한 array 변환 값 "255" 값이 포함되어 있어야 해요. 그렇지 못한 이미지의 경우에는 Numpy를 이용해 "0" 값을 "255"로 변환해서 사용할 수 있답니다.
수정 후
import numpy as np
from PIL import Image
# mask 적용할 이미지 가져오기
mask = np.array(Image.open("이미지 파일 경로"))
mask
Python
복사
결과)
array([[[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
...,
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]],
...,
Python
복사
보시다시피 255값이 포함되어 있지 않기 때문에 0값을 255로 변환시켜 볼게요.
# mask 적용할 수 있도록 색상값 변환하기
trans_mask = np.where(mask == 0, 255, mask)
trans_mask
Python
복사
결과)
array([[[255, 255, 255, 255],
[255, 255, 255, 255],
[255, 255, 255, 255],
...,
[255, 255, 255, 255],
[255, 255, 255, 255],
[255, 255, 255, 255]],
...,
Plain Text
복사
값이 변환되었으니 마스크를 적용해볼게요.
from wordcloud import WordCloud, STOPWORDS # WordCloud와 STOPWORD 호출
import matplotlib.pyplot as plt # matplotlib.pyplot를 plt로 단축
import numpy as np # 이미지를 array 데이터로 변환
from PIL import Image # 이미지 분석 및 처리
mask = np.array(Image.open("/content/drive/MyDrive/마케팅 스터디 뉴스레터/워드클라우드 생성/의료대란 키워드/의료대란.png")) # 이미지를 불어와 arrary 데이터로 변환
wc = WordCloud(width = 3000, height = 2000, random_state=1,
background_color='white', colormap='Set1',
collocations=False, stopwords = STOPWORDS,
font_path='./font/NanumBarunGothic.ttf',
mask=trans_mask)
wc.generate_from_frequencies(filtered_nouns_counter) # 워드 클라우드 생성
plt.figure(figsize=(10,10)) # 이미지 크기 지정
plt.imshow(wc, interpolation="bilinear") # 픽셀을 부드럽게 색으로 채움
plt.axis("off")
plt.show()
Python
복사
결과)

청진기 모양의 워드 클라우드가 생성됐어요! ‘정부’, ‘의대’, ‘응급실’, ‘전공의’, ‘집단행동’ 같은 단어들이 청진기 형태로 시각화된 모습인데요. 이 키워드들을 연결해보면 ‘의료대란’이라는 이슈를 심층적으로 이해할 수 있어요.
이처럼 단순히 트렌드를 요약해서 보여주는 것보다 워드클라우드 같은 시각화 자료를 활용하면 보다 흥미롭고 임팩트 있는 콘텐츠를 제작할 수 있답니다.
'데후배'들도 관심 있는 키워드로 워드클라우드를 만들어 포트폴리오에 활용해보세요!